Transformers opened a new door through Natural Language Processing, and it is the basis of LLMs, which outperforms the earlier NLP models such as RNN. Google introduced Transformers in 2017 in the paper entitled: Attention is all you need. In this tutorial, I tried to explain the architecture based on the Google paper in a simpler way.

Transformer architecture is based on the attention network. To understand how the atention mechanism works, see Attention Mechanism.
In the Attention equation we compute the attention value for a query, keys and values. In LLMs, all of the query, keys and values are words. Therefore, it is called self-attention. So that, we compute the attention values between each word and every other word.
The output of the self-attention network is a probability for every word in the text. During the training process the attention weights are stored. The weights corresponds the probabilty of a word that would be predicted.
The Multi-Head attention computes the attention for the pairs of words. It is called multi-head because, infact, we compute multiple attentions (self-attention).
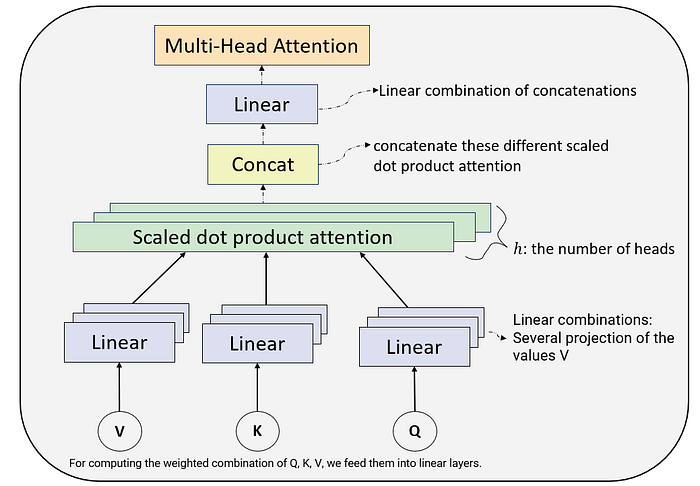
As illustrated in the above diagram, we concat the multiple sets of self-attention.
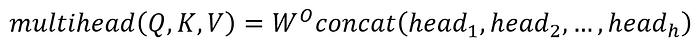
A head in Multi-head attention is a weighted combination of the key-value and the query. We compare the query to all keys in each head and compute the similiraity. The similiarity measurment is the weight of a key, so that the key with the greater similarity has the higher weight.
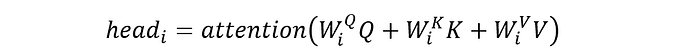
Network learns each set of self-attention weights or heads ndependently of each other. Therefore, we can parallelize such learning process.
For producing the sequence of word, each word should be connect to only the previous words and not the futute words. Therefore we need a mask to remove the dependency of each word to the future, which are not even being produced yet!
That’s why we need a mask to remove the links of the words to the future words by nullify their values.

To mask some of the values in multi-head attention, we should nullify the probabilities of such connection. Therefore, we won’t create any pairs that connect a word to the future.
Transformer has two parts: Encoder and Decoder. The encoder encodes the text, and the decoder produces the result. Before providing an insight into what each part does, let’s get familiar with three main phases for preparing the text in the encoder or decoder block.
The input is the full text or the sequence of words. However, the words should be turned into the number by tokenization. The numbers represent the position of the word in the sequence of words. The model will work with the tokenized words.
In this step, each token turns into a vector that results in a high-dimensional vector space called input embedding. The network learns to encode the meaning and context of each token in this space.
Since we care about the position of each word in the text, we need to preserve this information. Otherwise, the network considers the sequence of words as a bag of words so that it won’t be able to generate a meaningful text.
The positional encoding is a vector that captures information about the position of a word. We obtain the positional embeding by
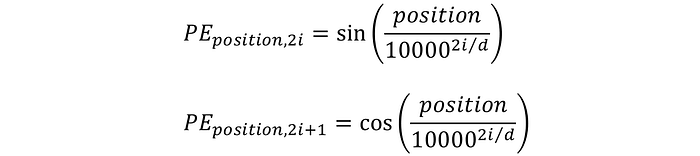
The position is a scaler, while the positional embedding is a vector of integers with the same dimensionality as the embedding of the word. Then, we add that to the embedding of the word.
Since the encoder block is repeated Nₓ times, every possible pairs of words in the input text is trained. The common value for Nₓ is something between 12 to 100.
In every iteration, the Multi-Head attention produces an embedding that takes the information of combination of words. When Nₓ = 0, we take the information of pairs of word, when Nₓ = 1, we take the information of pairs of pairs of word, and so on. Therefore, when we repeat the encoder block Nₓ times, we can take the information of a very large combination of the words.
The image bellow shows briefly what each part of the encoder part does.
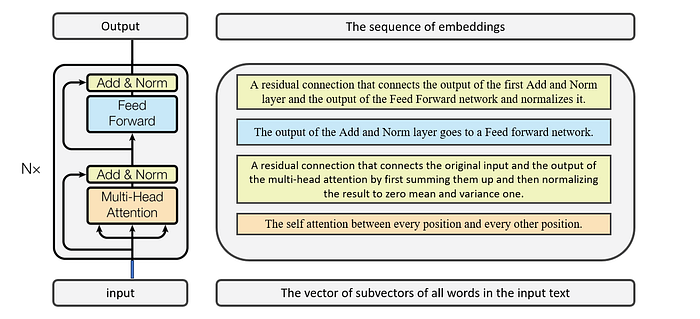
The output of the encoder block contains the information on the positions of the words and the information on the position of all other dependent words.
Some networks are Encoder-Only or Autoregressive models such as sentiment analysis or word classification. BERT and RoBERTa are two well-known examples of Encoder-Only models.
Decoder embeds and produce the output. Same as the encoder block, the output block is repeated Nₓ times. In the output block we gradually generate pairs of words. The generated sequence becoming better as we get close to the final block and produce an output.
The image bellow shows briefly what each part of the decoder part does.
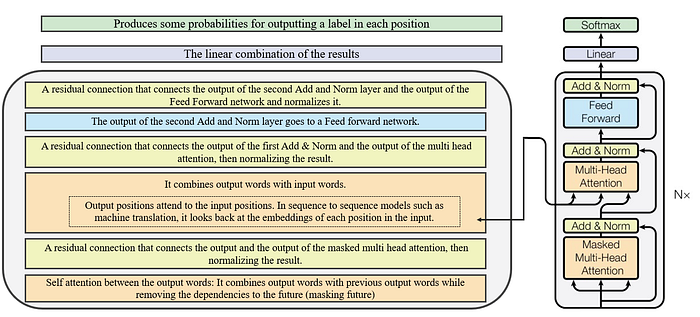
Some networks are Decoder-Only or Autoregressive models, which are used for text generation tasks. GBT and BLOOM are two well-known examples of Decoder-Only models.
The Encoder-Decoder models or the sequence-to-sequence model such as machine translations uses both the encoder and the decoder.